

数据质量是机器学习成功之“母”
引言
人工智能已经风行许久,目前不但有强大的配套基础设施和先进的算法,在市场上的应用也广泛增加。但是,这一切并没有让机器学习(ML)项目的落地变得容易。
 编辑搜图
编辑搜图
Source: Chat bot vector created by roserodionova - www.freepik.com
数据质量问题也不是什么新概念,自从机器学习开始应用以来,它就得到了人们的关注。机器从历史数据中不断学习,其结果的好坏与它的训练数据的质量密切相关。
以数据为中心vs 以算法为中心
在数据科学家的工作中,有两种情况时有发生:假设你已经完成了初步的探索性数据分析,并对模型的性能感到非常满意,但模型的应用结果不够好,不能被业务所接受。在这种情况下,考虑到研发的成本和时效,你的下一步计划是什么:
-
分析错误的预测,并将其与输入数据联系起来,以发现可能的异常和以前忽略的数据模式。
-
或者采用一种前瞻性的方法,模型采用更复杂的算法。
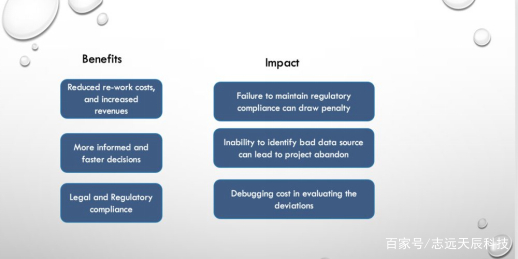
简而言之,如果不能向机器提供良好的输入数据,那么即使采用更先进的、更高精度的ML算法,也不会产生太好的效果。吴恩达(Andrew Ng)在他的讲座“MLOps:从以模型为中心到以数据为中心的AI”(MLOps: From Model-centric to Data-centric AI) 中很好地阐述了这一点。
数据质量评估
机器学习算法需要的训练数据是单一视图(即扁平化结构)。由于大多数组织维护多个数据库,通过组合多个数据源并将所有必要的属性提取出来,这一数据准备的过程是相当耗费时间和人力资源(需要专业技术人员)的。
在这一步骤中,发现的错误数据暴露于多个错误源,因而数据需要严格的同行评审,以确保建立的逻辑得到了正确的表达、理解、编程和实现。
由于数据库集成了多种来源的数据,与数据获取、清洗、转换、关联和集成相关的质量问题变得至关重要。
数据准备、清理和转换占用模型构建大部分时间大概是数据科学行业普遍共识。因此,建议不要匆忙地将数据输入模型,而要执行广泛的数据质量检查。虽然对数据进行检查的数量和类型可能比较主观,但我们还是有必要讨论一些在数据质量评估中的关键因素:完整性、独特性、时效性、一致性、准确性。
保证数据质量的技术:
-
缺失值填充
-
异常值检测
-
数据转换
-
降维
-
交叉验证
-
bootstrapping算法
质量!质量!质量!
下面让我们来看看如何提高数据质量:
-
不同的标注:数据是从多个来源收集的。不同的供应商对数据的最终用途有不同的理解,他们有不同的方法来收集和标记数据。即使在同一个数据供应商中,当主管得知需求并下达给不同的团队成员时,也会出现无数种标注方式,因为所有的团队成员都是根据自己的理解进行标注。
供应商方面的质量检查,对消费者方面的共同理解,将有助于形成同质化标注。
-
不同的记录:对模型的训练数据进行不同的聚类、转换操作,会产生重要的影响。例如计算滑动平均值、回填空值、缺失值估算等。这需要该领域的专家进行验证。
-
如何处理丢失的数据?系统缺失的数据会导致有偏差的数据集。此外,从有更多空值或缺失值的数据中删除这一属性(如性别或种族),可能会导致删除代表特定人群的数据。因此,错误表述的数据将产生有偏差的结果——不仅在模型输出水平上存在缺陷,而且也违背了负责任的使用人工智能的道德和公平原则。此外,另一种找到缺失属性的方式也可能是“随机”的。由于高缺失值,盲目地删除某个重要属性会降低模型的预测能力,甚至损害模型。输入缺失值的最常见方法是通过计算类似维度或级别上数据的平均值。
-
扁平化结构:大多数组织都缺少一个集中的数据库,且缺乏结构化数据是采用机器学习模型进行决策的关键问题之一。例如,网络安全解决方案需要将来自多个资源(如网络、云和端点)的数据归一化到一个视图中,以便针对此前发生的网络攻击或威胁进行算法训练。
 编辑搜图
编辑搜图
规模化理解数据
前文已经讨论了一些可能会引起数据质量下降的关键之处,接下来我们将通过使用TensorFlow来看看如何来规模化理解数据:
-
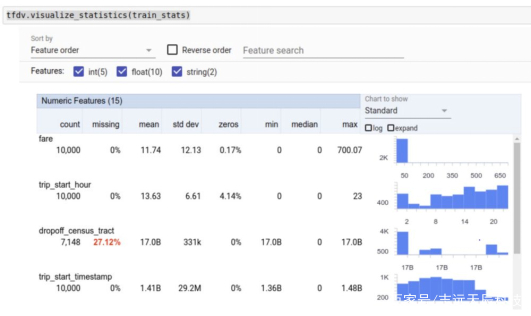
使用TFDV进行统计分析,显示数据的统计分布——均值(mean)、最小值(min)、最大值(max)、标准差等。
-
理解数据模式非常关键——包括特性、数值和数据类型。
-
一旦你理解了数据分布,持续对异常行为进行跟踪也是很重要的。TFDV突出域外值,从而指导误差的检测。
-
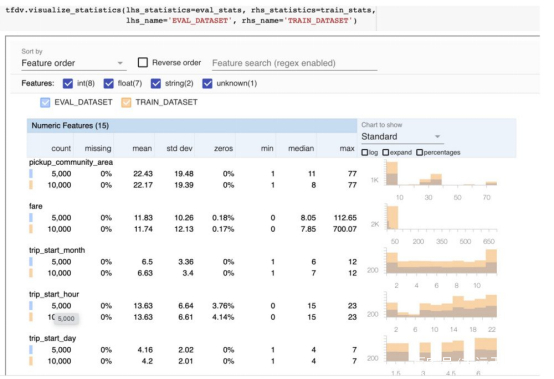
它通过叠加训练数据和测试数据的分布,来显示训练数据和测试数据之间的漂移。
TensorFlow的文档说明了使用TFDV分析数据并提高其质量的方式,感兴趣的话可以在数据集上尝试使用合作平台Colab中的TFDV代码。
谷歌在这个Colab平台中分享了一段代码,对出租车的数值数据和分类数据的统计分析如下:
 编辑搜图
编辑搜图
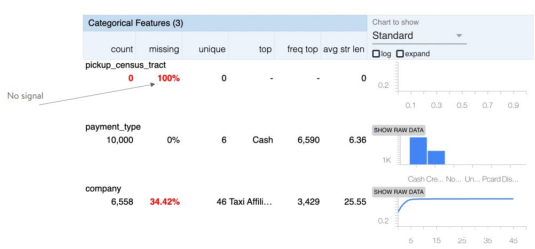
右边显示的缺失值的占比有助于更好地理解数据。
 编辑搜图
编辑搜图
pickup_census_tract代表完全缺失值的记录,对ML模型来说毫无意义,可以采用EDA算法对其进行过滤。
数据漂移是部署模型当中不可避免的现象,可能在训练数据和测试数据之间产生,也可能在训练数据进行几天训练之后产生。
ML算法是在训练数据和测试数据具有相似特征的假设下执行的,违反这一假设将导致模型性能下降。
 编辑搜图
编辑搜图
参考文献
《启用Tensorflow数据验证》(Get started with Tensorflow Data Validation)
译者介绍
张怡,51CTO社区编辑,中级工程师。主要研究人工智能算法实现以及场景应用,对机器学习算法和自动控制算法有所了解和掌握,并将持续关注国内外人工智能技术的发展动态,特别是人工智能技术在智能网联汽车、智能家居等领域的具体实现及其应用。
